For a number of years, professional graphics specialists, Nvidia and AMD, have been extolling the virtues of using graphics cards to perform computationally intensive tasks usually carried out by CPUs. It might sound like a bizarre concept, but graphics processing units (GPUs) are actually made up of tens and sometimes hundreds of parallel processors, which in theory make them ideal for highly parallel processing tasks, including simulation and rendering. When used for calculations other than pure graphics, the GPU is often referred to a General Purpose Graphics Processing Unit (GPGPU).
As with any new technology, once the foundations are laid it takes a while for the software developers to catch up. And while there have been a number of niche GPGPU applications developed in areas such as finance, science and medical, we are only just starting to see this technology appear in mainstream Computer Aided Engineering (CAE) software.
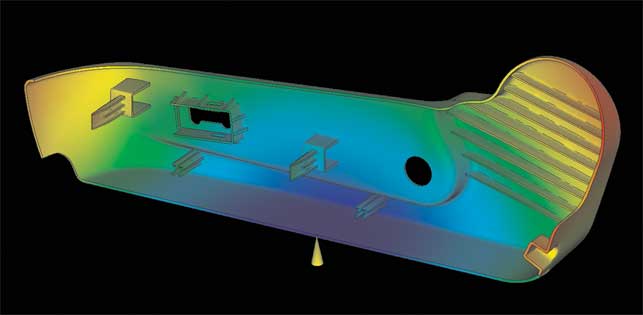
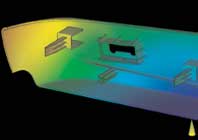
The prediction of plastic flow into a mould can now be simulated using CUDA-enabled graphics cards
One of the first CAE vendors to bring a GPGPU solution to market is Autodesk with Moldflow Insight 2010, an application that is used to simulate plastic flow in injection-moulded components. The technology is based on Nvidia’s CUDA parallel processing architecture, which harnesses power from the company’s high-end Quadro FX and GeForce graphics cards, as well as its dedicated Tesla GPGPU boards.
Autodesk’s implementation of CUDA inside Moldflow Insight 2010 is actually part of a major rewrite of the software’s solver code. Prior to the 2010 release, Autodesk licensed a single-threaded technology from Allied Engineering for its solver. This meant it could only take advantage of a single CPU core (or processor).
With customer models increasing in their complexity, Autodesk was hearing that simulations often took too long to complete. However, instead of just re-writing its matrix solver to take advantage of multiple CPU cores (multi-threaded) Autodesk went the whole hog and programmed its solver to utilise GPU processing at the same time. The new multi-threaded solver covers two distinct areas of analysis – warpage and the prediction of plastic flow into a mould. There is no limit to the number of CPU cores it can take advantage of but there are diminishing returns as you use more.
Most current high-end dual processor workstations feature eight cores (Intel) or twelve cores (AMD) and this is likely to increase soon. But in addition to all of this multi-core processing power, the new solver can use the computational resources of a CUDA-enabled graphics card, which it treats as an additional core.
Users can specify how many of their workstation’s cores they want to use on each simulation and a tick box defines whether or not GPU acceleration is used. If multiple simulations are being run concurrently, the system is intelligent enough to dedicate specific cores to each job.
GPU acceleration on test
We were extremely interested to find out how the new solver code performed with Nvidia’s CUDA technology and tested it out using an HP Z600 workstation with two Intel Xeon (Nehalem) E5530 processors (2.4GHz), 6GB (6 x 1GB) DDR3 memory, a Quadro FX 4800 (1.5GB) graphics card, and Windows Vista Business x64.

Nvidia Quadro FX4800: Just one of the CUDA-enabled graphics cards used to accelerate solve times in Moldflow
We ran a combination of models on 1, 2, 4 and 8 CPU cores with GPU acceleration enabled and disabled. Starting off with a 25,000 tetrahedron model (which is very small for a plastic flow simulation study) we found that there was no benefit when using GPU acceleration. This was because the problem was too small to benefit from the parallel solver.
Moving to the other end of the spectrum we threw a giant 2.4 million tetrahedron model at the workstation and while solves times were cut as additional CPU cores and GPU acceleration were used, the sheer size of the problem meant that both the 6GB system memory and the 1.5GB graphics card frame buffer memory were often saturated which slowed the whole process down and made the testing unreliable.
We settled on a 620k tetrahedron model and this gave consistent, repeatable results. Solve times reduced as more CPU cores were added and GPU acceleration cut the solve times further (see Fig 1).
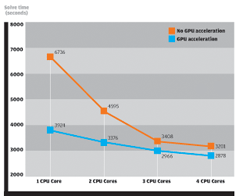
Fig 1: Chart showing solve time of 620k tetrahedron model in Moldflow Insight 2010 with and without GPU acceleration
The biggest percentage decrease came when moving from one to two CPU cores and when using GPU acceleration on top of a single CPU core. There were diminishing returns as more CPU cores were added, both with and without GPU acceleration.
The most interesting discovery came when running multiple simulations at the same time. Firstly we ran two concurrent 620k tetrahedron simulations – one using four CPU cores and the second using the other four CPU cores with GPU acceleration (see table below). It’s interesting to note that the solve times were not that much slower than when running each simulation on its own.
Next up we ran four concurrent 620k tetrahedron simulations – three of them on two CPU cores apiece and the other on two CPU cores with GPU acceleration.
While the solve time of each test was slower than if running them individually, the cumulative time was much quicker than if running each test in serial using all available compute resources. It should be noted that with this test, the system memory was very close to its 6GB limit and may have reached saturation at times, so this may have had an impact on solve times.
We were also interested to see how 3D graphics performance was affected when running GPU-accelerated simulations and carried out some frame rate tests inside a CAD application. We experienced a 20-30% performance drop in terms of frame rates, regardless of whether one or eight CPU cores were being used. There was also a similar drop in 3D performance when the solver was running without GPU acceleration, so we concluded this was largely down to a bottleneck occurring in the CPU or system memory.
Conclusion
Autodesk’s implementation of CUDA in Moldflow Insight is one of the first in the mainstream CAE sector and for this reason alone it’s an exciting development. However, because multi-core CPUs also work very effectively with the new solver code this excitement could easy get lost in the mountain of processing power available in today’s high-end workstations.
The fact is that Intel’s (Nehalem) Xeon-based processors are particularly adept at running multi-threaded code due to the memory controller being integrated inside the CPU.
With this in mind those with workstations based on older architectures, such as Core 2 Duo (for which memory was often a bottleneck with multithreaded code) are likely to benefit more from GPGPU acceleration.
With many different variables affecting performance, finding the combination of hardware that offers best price/performance will be no easy task, particularly as performance varies according to the size and type of the simulation. But for those seeking ultimate performance, a dual processor workstation with plenty of RAM and a high-end CUDA GPU card will be first past the post every time.
www.autodesk.com/moldflow / www.nvidia.com/cuda
The importance of CPU and GPU memory
As with any simulation application, analysis problems in Moldflow Insight can be limited by the amount of memory residing on the workstation. A very rough rule of thumb is that for every one million tetrahedrons there are in the mesh, 1GB of memory is required. While the workstation’s system RAM can always be increased, if you work with particularly large models you could quickly find yourself running out of GPU memory, which is fixed on the graphics card.
Before each analysis starts, the software checks to see if there is enough memory for it to proceed and if there isn’t it will automatically switch over to the CPU, rendering the GPU redundant as far as its compute capabilities are concerned. Further checks are also carried during the analysis.
Because the graphics card is also likely to be needed for 3D graphics, the software is able to release power as an when required so the workstation can still be used for 3D modelling at the same time as running a simulation.
Choosing the right CUDA-enabled GPU
Nvidia offers a whole range of CUDA-enabled GPU products, but not all are compatible with Moldflow Insight. Only those with a CUDA compute capability of 1.3 can be used and these currently include certain Quadro FX (professional 3D), GeForce (consumer 3D) and Tesla (high performance computing) cards.
For Quadro, the compatible cards are the FX 1800 (768MB), FX 3800 (1GB), FX 4800 (1.5GB), FX 5800 (4GB). For GeForce, it’s the GTX 260 (896MB), GTX 280 (1GB), GTX 285 (1GB), and GTX 295 (1.8GB). For Tesla, it’s the C1060 (4GB), but it’s important to note that Tesla boards are dedicated GPGPU boards and not graphics cards, so a standard workstation graphics card will also required.
Choosing the card most appropriate to your needs depends on many factors including performance, on-board memory, compatibility and price.
For performance, the more CUDA parallel processing cores the card has, the more powerful it is. For example, the Quadro FX5800 and Tesla C1060 both feature 240 cores, making them significantly more powerful than the Quadro FX1800, which only has 64.
A large amount of on-board memory is required for complex simulations and if there is not enough the simulation simply won’t run (see page 44 for more info). For compatibility, it’s important to check
that your workstation is up to the job as high-end GPUs draw lots of power, take up additional space and require specialist electrical connectors.
In terms of price, top-end Quadro FX cards are very expensive, and these could also be overkill as Moldflow itself doesn’t have big requirements for 3D graphics. For ultimate GPU performance money may be best spent on the more cost-effective Tesla C1060 card (which is virtually identical to the Quadro FX 5800) but this will need to be backed up with a low cost Quadro FX card for 3D graphics.
For those on a budget, consumer GeForce cards are much cheaper than professional Quadro FX cards, and while they are not recommended for 3D graphics in many CAD applications, they are designed to run CUDA applications in exactly the same way. The GeForce GTX 260 is available for around £140, which is a lot cheaper than the Quadro FX 1800.
If a workstation has two compatible cards, Moldflow Insight will automatically use the one with the most memory.
Moldflow Insight 2010 is using GPU power to solve complex simulations