Back in May Nvidia told DEVELOP3D that there was going to be some big news later this year regarding some of the major CAE (Computer Aided Engineering) software developers taking advantage of GPUs (Graphics Processing Unit) to accelerate solve times. Well, as far as CAE software developers go, they don’t come much bigger than Ansys, and the company has just announced details of a GPGPU (general-purpose GPU) accelerator capability inside a preview version of Ansys 13.0.
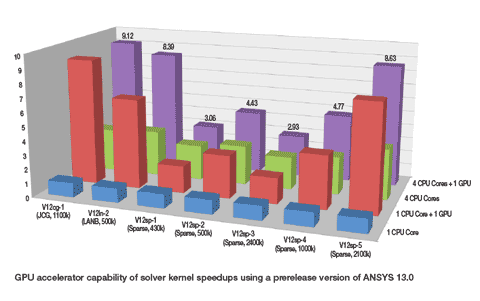
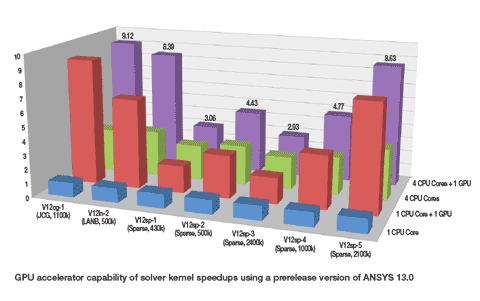
According to Ansys, by using GPGPUs, or more specifically Nvidia Tesla GPUs, it has been able to ‘dramatically reduce overall engineering simulation processing time by as much as half’ – an amount of time not to be sniffed at. Of course, all performance claims need closer inspection and it is important to note a couple of things, which are explained in more depth in this informative Ansys report.
1) This initial development only works with shared-memory equation solvers – i.e. those that take place within a single workstation – and 2) the reduction in processing time is compared to a single quad core Xeon chip.
As a result, the Ansys GPU accelerator will only really be of benefit to those who carry out simulation on a desktop workstation, and not on a distributed cluster, which is where high-end simulation usually takes place.
However, Ansys explains that this is just the beginning for GPU acceleration in its software, and while the technology only currently works on CUDA hardware (i.e. Nvidia Tesla (Fermi) boards) it is investigating the use of AMD/ATI GPU cards, presumably using OpenCL. It also states that it is looking at the potential for supporting multiple GPUs and Distributed Ansys, which would have a much bigger impact on the future of high-end simulation and help give real potential to GPU-based cloud computing.